마크다운 만들기 - Markdown [3/3]
Table of Contents
모헤윰의 에디터 만들기 시리즈 모아보기
에디터 만들기 - ContentEditable [1/3]
에디터 만들기 - getSelection [2/3]
에디터 만들기 - Markdown [3/3]
마지막입니다. 입력하고, 게시할 수 있게 되었으니, 이제 남은 일은 서식을 적용하는 것 뿐입니다. 마크다운 문법을 이용해 어떻게 서식을 적용할 수 있을까요? 그 과정을 정리해 보겠습니다.
🤷 어떻게 할까요?
정말이지 어떻게 하면 좋을까요? 우선 제가 생각하는 가장 사용성이 좋은 마크다운은 깃허브의 그것이였습니다. GFM(GitHub Flavored Markdown)이라고 부르는 스펙이 있는데, 처음에는 이걸 부르는 이름이 있는 것조차 모르고 막무가내로 리버스 엔지니어링 마인드로 작업을 시작했습니다. 아래 사진처럼 아무 이슈나 들어가서 댓글 창에 실험을 하면서요.
원래대로라면 입력을 토큰으로 분해하고, Parse tree를 구성하여야 겠지만, 마크다운이 느슨한 언어이기 때문에 토큰으로 분해하는 과정이 지나치게 어려울 것이라 판단하여 쉬운 길을 선택하기로 했습니다. 그래서 자주 쓸 법한 마크다운 몇 가지만 적용할 수 있게 하면 되겠지? 하는 생각으로 깃허브를 열어서 아무 텍스트를 마구 입력해 보기 시작했습니다. 가벼운 마음으로요.
function headers(str: string): string {
let result = str.replace(/^### ([\S ]+)$/gm, "<h3>$1</h3>");
result = result.replace(/^## ([\S ]+)$/gm, "<h2>$1</h2>");
result = result.replace(/^# ([\S ]+)$/gm, "<h1>$1</h1>");
return result;
}
function code(str: string): string {
const result = str.replace(/`([\S\n][^`\n]+)`/gm, "<code>$1</code>");
return result;
}
function divideLines(str: string): string {
const result = str.replace(/^[\n]?([\S ]*)$[\n]?/gm, "<div>$1</div>");
return result;
}
export default function doParse(str: string): string {
let result = str;
result = headers(result);
result = code(result);
result = divideLines(result);
return result;
}
그렇게 만들어진 것이 저번 포스트의 마지막 사진입니다. 대충 이런 느낌으로 replace를 쌓아 나가면 되지 않을까요?
📝 뭐든 계획을 세우자
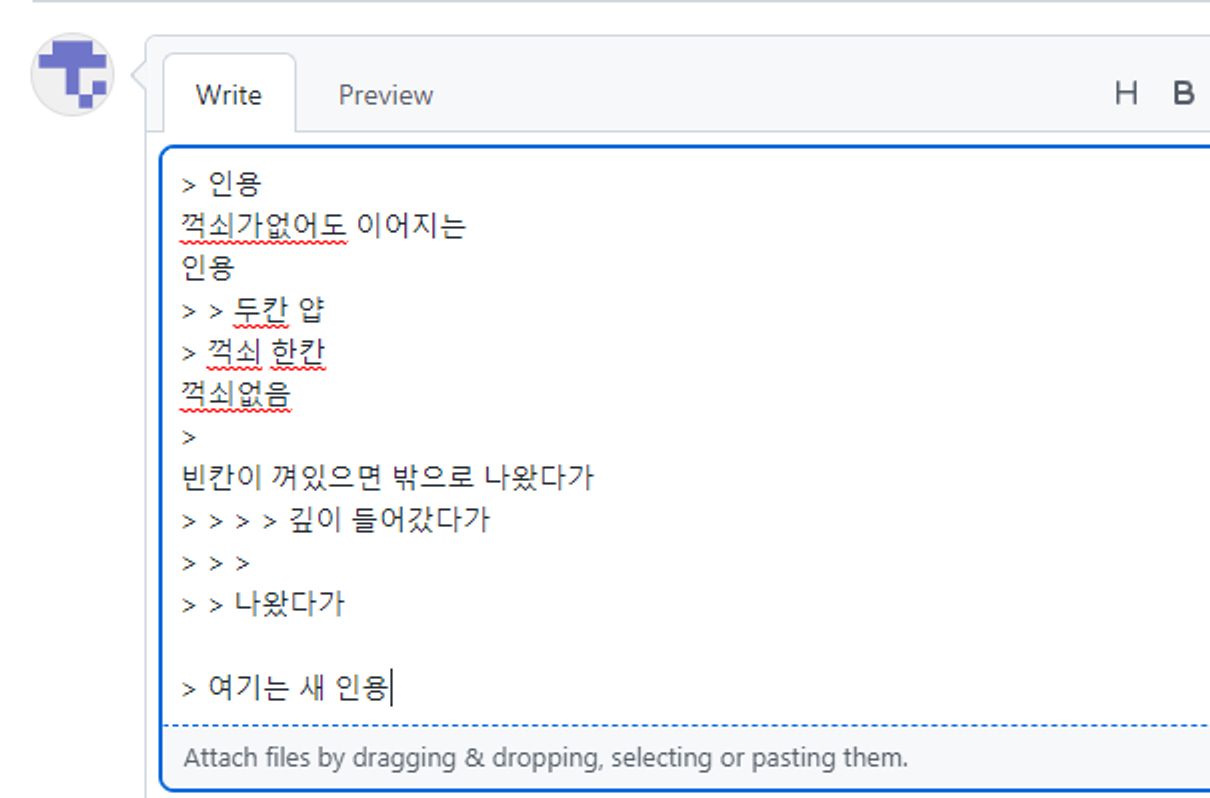
하지만 마크다운의 세계는 그렇게 만만하지 않았습니다. replace를 쌓아 나간다는 생각에는 변함이 없었지만 여러 줄에 걸친 문법이나 같은 식별자를 사용하는 문법을 어떻게 구별할 것인지와 같은 각종 예외 상황들을 어떻게 피해서 설계할 수 있을지 머리가 아파오기 시작했습니다. 특히 인용문은 아래처럼 다양한 경우에 대한 처리가 필요했죠.

이런 복잡한 경우에 대한 해답을 매 번 깃허브에 직접 입력해 보면서 결과를 맞춰 튜닝을 하느니, 차라리 처음부터 체계를 잡고 가자는 생각이 들어 GFM 스펙 문서를 읽으며 문법들을 정리하기 시작했습니다.

결과적으로 마크다운 문법은 크게 아래와 같이 분류할 수 있었습니다.
- 줄 전체에 적용되는
Block문법과 줄의 일부분에만 적용되는Inline문법이 존재합니다. Block문법은 부분적으로Inline문법을 포함할 수 있습니다.Block문법 역시 다른Block을 포함할 수 있는Container Blocks와 그렇지 않은Leaf Blocks로 나뉩니다.
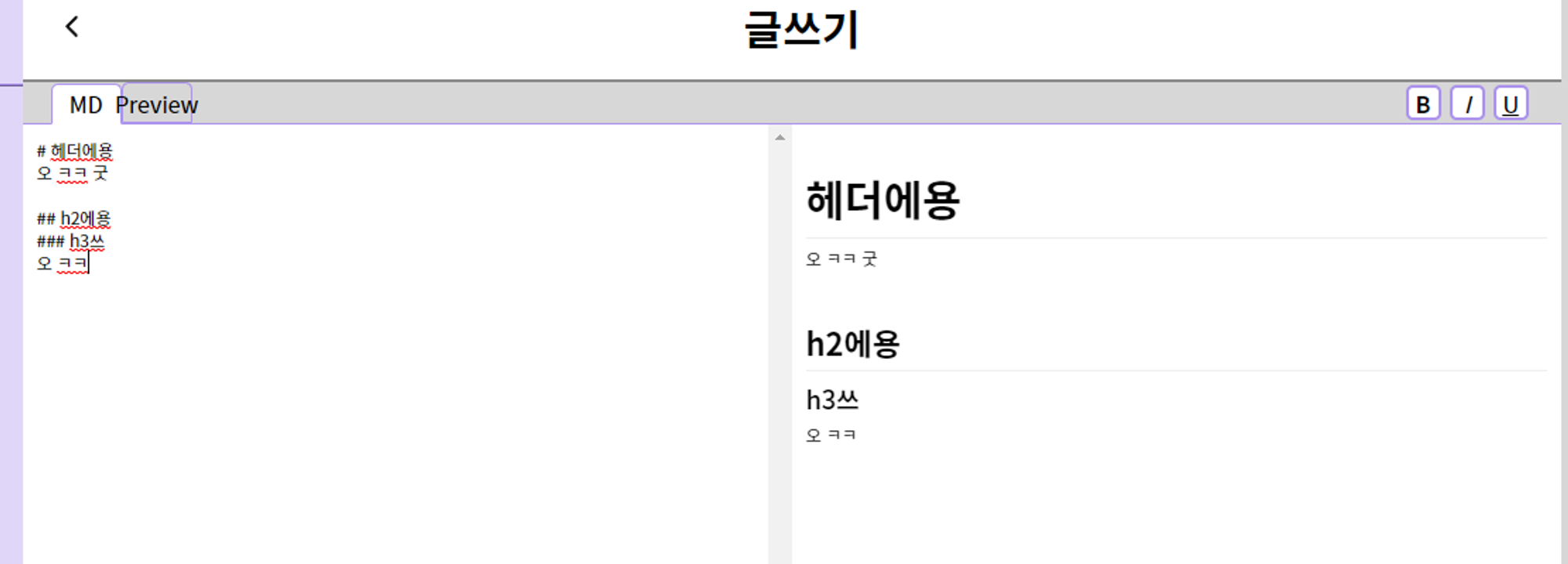
그리고 사진에 보이는 것처럼 각 문법에 대한 간략한 규칙을 정리하고, 지나치게 복잡하거나 자주 사용되지 않는 규칙들을 따로 표시하였습니다. 이제 이것들을 이용해서 각 문법들을 구현하고, Container Blocks → Leaf Blocks → Inlines 순서대로 변환해 주면 될 것 같습니다.
export function doParse(str: string): string {
let result = str;
result = blockQuote(result);
result = emptyLines(result);
result = headers(result);
result = code(result);
result = divideLines(result);
result = codeBlock(result);
result = hr(result);
result = bold(result);
result = italic(result);
result = underline(result);
result = strike(result);
result = link(result);
return result;
}
⚒ 좀 더 개선해보자
적용 범위가 큰 문법부터 차례대로 적용해 나감으로써 inline문법 안에 block문법이 적용된다거나 하는 문제를 예방하였고, 각 줄을 div 태그로 변환하는 시점을 조절해서 정규표현식의 div가 필요한 부분에만 들어가도록 더 온전한 결과물을 만들 수 있었습니다.
그런데 codeBlock과 link, image의 URL은 마크다운의 영향을 받지 않아야 하는데 underline이나 bold같은 문법이 적용되고 있습니다. 이를 위해 첫 변환시 placeholder 역할을 하는, 일반적으로 입력할 수 없는 문자로 치환하고, 원본 텍스트를 마지막에 다시 재변환하는 작업을 진행하였습니다. 또 중간에 연속되는 변환 과정을 하나의 pipe 함수로 묶어주면 좋을 것 같네요.
export function doParse(str: string): string {
let result = str;
let codes: string[] = [];
let links: string[] = [];
let imgs: string[] = [];
[result, codes] = codeBlock(result);
[result, links, imgs] = link(result);
result = pipe(
blockQuote,
unorderedList,
orderedList,
emptyLines,
headers,
code,
divideLines,
hr,
bold,
italic,
underline,
strike
)(result);
result = recoverPlaceholders(result, codes, "\u235e");
result = recoverPlaceholders(result, links, "\u235f");
result = recoverPlaceholders(result, imgs, "\u2360");
return result;
}
🔥 마치며
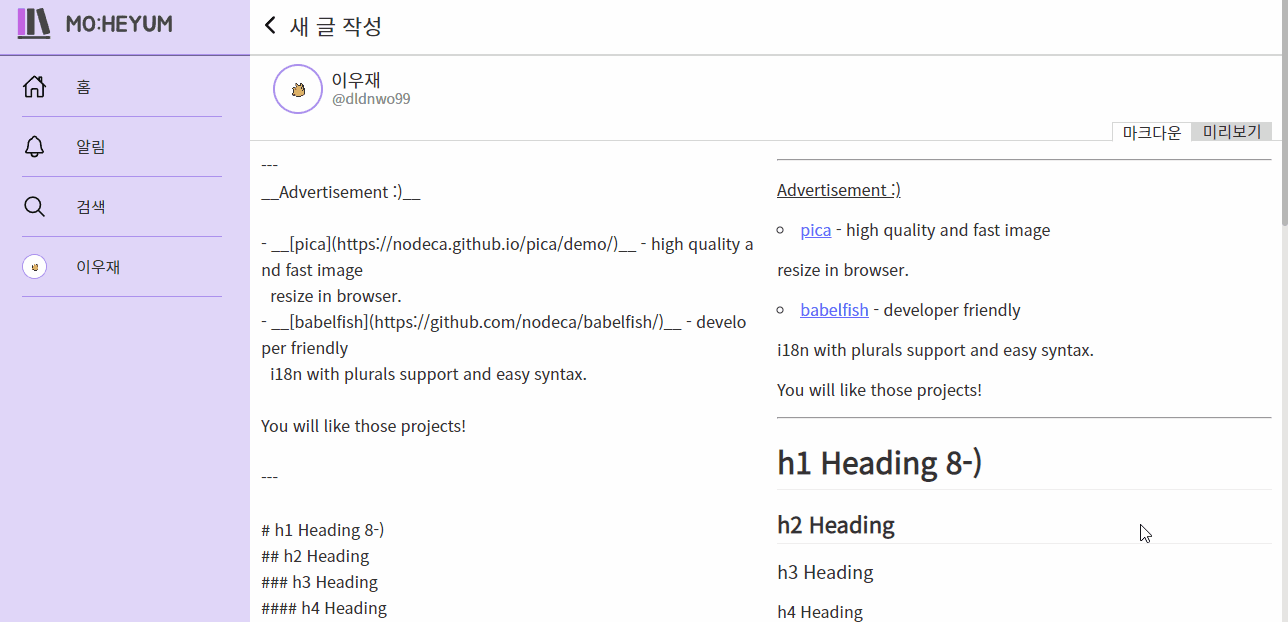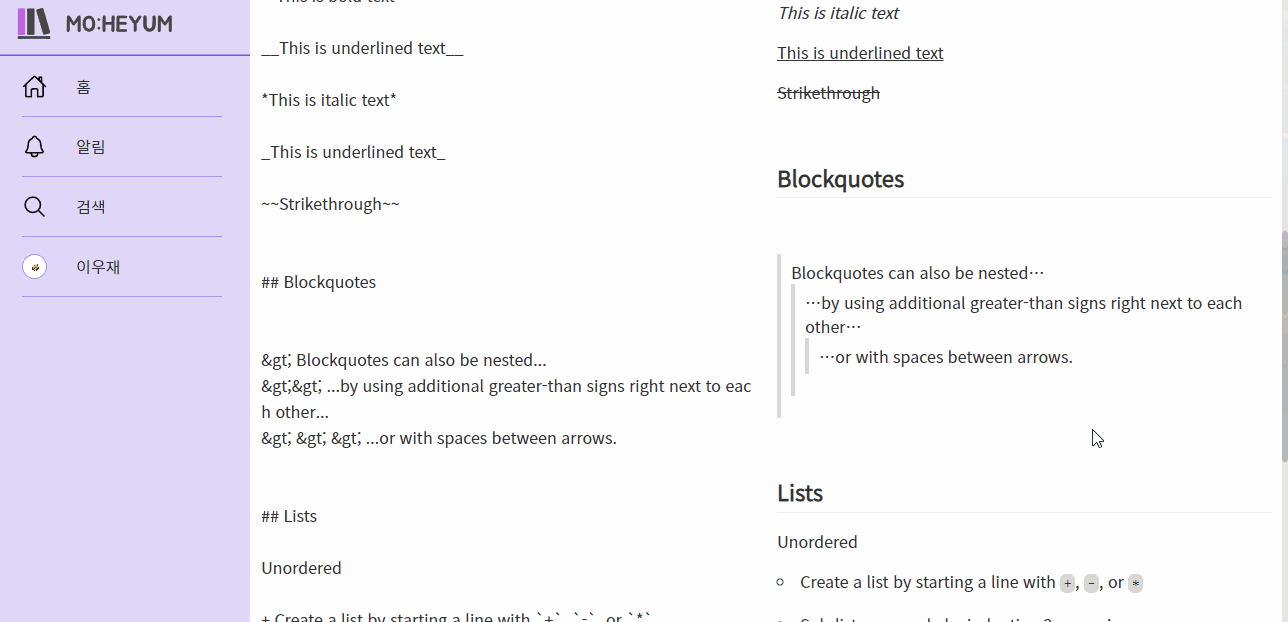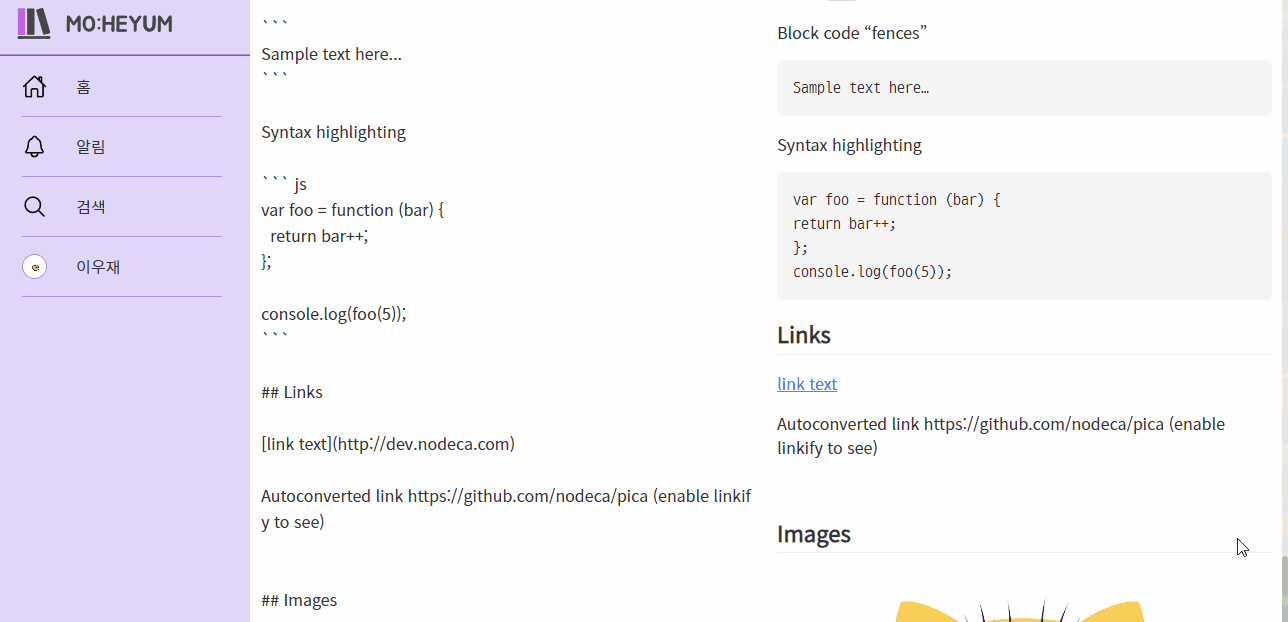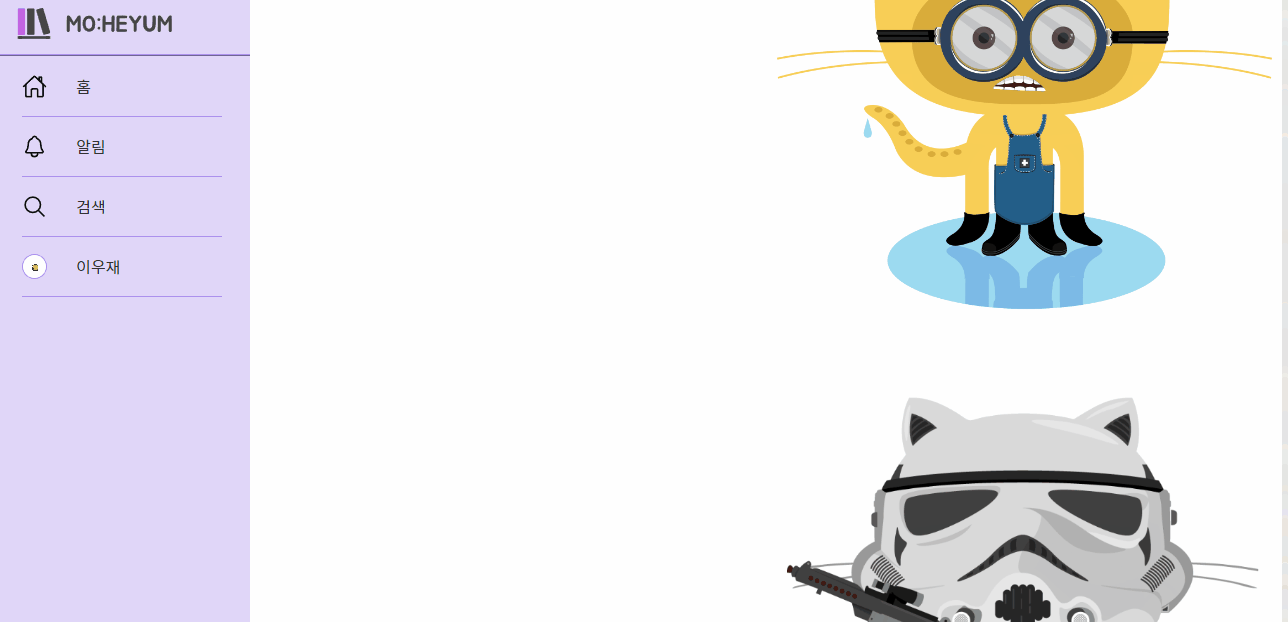
처음에 시작할 때에는 무척 거창하게 시작했는데, 생각보다 투박한 결과물이 나왔습니다. 그래도 뭔가 라이브러리의 힘을 빌리지 않고 이 정도를 구현했다는 데 의의를 두고 싶습니다. 특히 에디터같은 부분은 찾아 볼수록 더 많은 기능이 필요하다는 것을 알게 되어서 아쉬움이 더 많이 생겼습니다. 나중에 시간이 되면 undo 기능도 구현하고, 이것저것 더 개선해 보고 싶네요.
지금까지 모헤윰의 마크다운 에디터를 구현한 과정이였습니다.