SEO - 3. 사이트맵과 구조화된 데이터
봇에게 페이지 요약을 제공하자
작성일:
이전 글에서, 크롤링 봇이 이해하기 좋은 페이지를 만드는 것이 중요하다고 언급한 바 있다. 크롤링 봇이 사이트의 내용을 이해하지 못한다면 크롤링이 불가능하고, 당연히 검색 결과에도 페이지가 표시될 수 없다. 그렇다면 크롤링 봇은 단순히 사람처럼 페이지 내용을 읽는 것 만으로 사이트를 이해하는 것일까? 물론 아니다. 봇이 페이지를 이해하기 쉽도록 정보를 제공해 주는 수단은 여러 가지 있는데, 오늘은 사이트맵과, 구조화된 데이터 및 메타 데이터에 대해 다룰 것이다.
사이트맵 - 봇에게 사이트의 지도를 제공하자
사이트맵이란, 사이트에 있는 페이지, 동영상 및 기타 파일과 각 관계에 관한 정보를 제공하는 파일이다.(사이트맵이란 무엇인가요? - Google 검색 센터) 통상 사이트맵은 이 사이트에 어떤 페이지들이 있는지, 그 주소의 목록을 제공한다. 그 외에 동영상이나 이미지 같은 콘텐츠에 대한 정보를 포함할 수도 있다. 사이트맵은 보통 아래와 같이 생긴 xml 문서이다.
<?xml
version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:news="http://www.google.com/schemas/sitemap-news/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml" xmlns:mobile="http://www.google.com/schemas/sitemap-mobile/1.0" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1" xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
<url>
<loc>https://prayinforrain.github.io</loc>
<lastmod>2025-06-25T01:22:43.182Z</lastmod>
</url>
<url>
<loc>https://prayinforrain.github.io/about</loc>
<lastmod>2025-06-25T01:22:43.183Z</lastmod>
</url>
<!-- ... -->
</urlset>
사이트맵에 대해 알아야 할 정보들을 나열해보자.
- 페이지의 url(
loc), 최근 수정일(lastmod), 페이지 갱신 빈도(changefreq) 등의 속성이 있지만, 대부분의 경우loc속성만이 활용된다. - 사이트맵 파일 하나가 지나치게 많은 링크를 포함하거나 용량이 크면 크롤링이 안될 수 있다. 구글의 경우, 하나의 파일에 50MB 및 50,000개 이하의 URL만을 허용한다.
- 사이트맵이 지나치게 큰 경우 사이트맵 색인 파일로 여러 개의 사이트맵 목록을 제공하는 하나의 색인 파일을 제출하면 된다.
사이트맵 만들고 제출하기
사이트맵을 생성하는 방법은 여러 가지가 있다. 보편적으로 적용할 수 있는 방법은 XML-sitemaps를 사용하는 것이다. 여기에 사이트 URL을 넣으면 사이트맵을 자동으로 생성해준다. 또는 사용하는 기술스택(React, Next.js 등)에 따라 사이트맵을 생성해 주는 라이브러리를 활용해서 배포 시 자동으로 사이트맵이 생성되도록 할 수도 있다. 이 블로그의 경우 next-sitemap을 사용하여 배포시 자동으로 사이트맵을 생성한다.
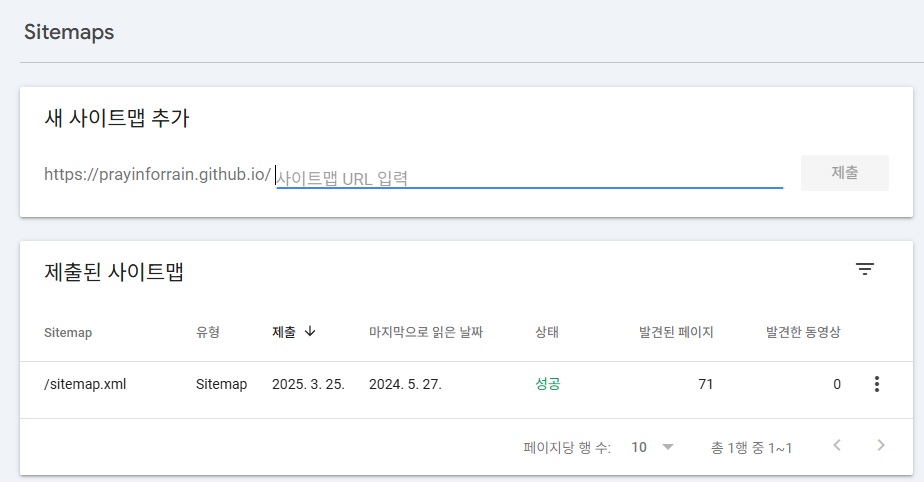
이제 생성한 사이트맵을 봇이 찾을 수 있도록 해야 한다. robots.txt에 Sitemap 속성을 사용해 사이트맵의 위치를 명시하거나, 검색 엔진 콘솔에서 직접 사이트맵을 제출할 수도 있다.
페이지 메타데이터와 구조화된 데이터
HTML의 head 요소에는 페이지에 대한 정보들이 포함된다. <meta name="description" content="..."/>과 같은 태그를 본 적이 있을 것이다. 이런 태그들은 브라우저와 봇에게 이 페이지가 어떤 내용을 담고 있는지에 대한 요약된 정보를 제공한다. 여기서 작성된 내용이 검색 결과에 바로 반영되기도 하고, 일부 SNS는 meta 요소에 opengraph 등의 속성을 정의하여 링크 미리보기 등에 사용하기도 한다. 그러니 반드시 신경써서 관리하는 것이 좋다. 구글 검색 센터와 Opengraph를 참고하자
meta 요소 외에도 페이지에 대한 요약을 제공하기 위해 사용되는 것이 있다. 구조화된 데이터라고 하는 것인데, 웹에 게시된 콘텐츠에 대한 정보를 담은 데이터로, 단순히 페이지에 대한 설명이나 썸네일 정도만 정의할 수 있는 meta 요소와 다르게, 콘텐츠 작성자에 대한 정보나 평점, 페이지 내에서 취할 수 있는 액션같은 정보도 상세하게 정의할 수 있다.
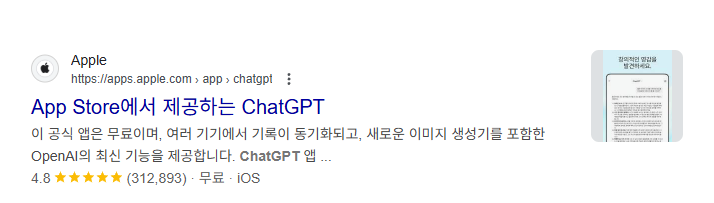
예를 들어, 어플리케이션에 대한 정보를 검색하면 단순히 썸네일과 페이지 내용만 표시되는 것이 아니라, 앱의 가격이나 평점까지 같이 표시되기도 한다. 검색 결과에서 콘텐츠가 표시되는 형태를 검색 스니펫이라고 부르는데, 애플 앱스토어 역시 구조화된 데이터를 활용하여 추가 정보를 제공하고 있다.
구조화된 데이터를 작성하자
구조화된 데이터는 schema.org에 자세한 설명이 나와 있다. 필요한 정보에 대한 요약만이 필요하다면 Google 검색 센터나 네이버 웹마스터 가이드를 참고하면 편하다. 검색엔진마다 지원하는 속성은 조금씩 다르지만, 서로 다르게 이해하는 경우는 없다. 따라서 사이트에서 스니펫이 지원되는 콘텐츠를 제공하고 있다면 그 부분만 선택해서 추가하면 된다. 이를테면 애플 앱스토어처럼 소프트웨어 앱을 제공하는 경우 head 요소에 다음과 같이 작성한다. 내용은 Google 검색 센터의 구조화된 소프트웨어 앱 데이터를 참고해서 작성했다.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "SoftwareApplication",
"name": "ChatGPT",
"description": "iOS용 ChatGPT를 소개합니다. 이제 OpenAI의 최신 기술을 손끝에서 경험해 보세요.\n\n이 공식 앱은 무료이며, ...",
"operatingSystem": "iOS 17.0 버전 이상이 필요. iPhone, iPad 및 iPod touch와(과) 호환.",
"applicationCategory": "생산성",
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": 4.8,
"ratingCount": 313779
},
"offers": {
"@type": "Offer",
"price": 0,
"priceCurrency": "KRW",
"category": "free"
},
"author": {
"@type": "Person",
"name": "OpenAI",
"url": "https://apps.apple.com/kr/developer/openai/id1684349733"
}
}
</script>
그 외에 추가할 만한 것들은 QnA, 영화 정보, 뉴스와 같은 것들이 있다. 검색엔진들은 각각의 가이드에서 자신들이 지원하는 스니펫들을 모두 알려주고 있으니 가이드의 예제들을 참고하면 쉽게 작성할 수 있으며, 이것들을 작성하더라도 스니펫이 100% 적용되는 것은 아니니 지나치게 집착하지 않도록 하자. 느낌 상 트래픽이 많고 일관된 콘텐츠를 제공할수록 더 잘 적용해 주는 듯함..
마치며 - AI 검색의 시대
최근에는 SEO의 중요성에 대해 의문을 제기하는 글들이 많이 보인다. 이유인 즉슨, 사용자들은 점점 직접 검색하는 대신 LLM에게 정보를 찾아오라 시키기 때문에 SEO의 가치가 예전 만큼 높지 않다는 것이다. 꽤 오랜 시간 SEO에 시간을 투자한 나에게는 반갑지 않은 주장이지만, 나도 예전에 비해 LLM을 사용해 1차 가공된 정보에서 원문을 찾아가는 식으로 검색을 하기 때문에 어느 정도 공감하는 바이다.
그럼 SEO는 이제 필요 없는 구시대적인 요소일까? 그건 아니다. 사용자가 직접 검색을 하진 않지만 LLM도 결국 검색을 해서 사용자에게 정보를 제공한다. 즉 사이트와 사용자 사이에 검색엔진이 껴있던 상황에서 LLM이 새롭게 추가된 상황이다.
정리하면, AI 검색의 시대에는 SEO의 패러다임이 바뀌는 것이 아니라 기존 SEO에 +@가 추가된 셈이다. 여전히 1차적으로는 검색엔진에서 상단에 노출되기 위해 노력해야 하고, 그렇게 LLM이 페이지에 유입되었을 때 만족한 정보를 얻어갈 수 있어야 한다. 다만 현재로서는 검색엔진과 LLM 둘 다 봇이기 때문에 기존의 SEO 방법론에서 무엇이 달라지는지 뚜렷한 결론이 나고 있지는 않다.
그럼에도 SEO에 대한 이해가 개발자에게 주는 인사이트는 뚜렷하다. SEO의 기조는 (콘텐츠의 질을 제외하면) 봇이 이해하기 쉬운 페이지를 만드는 것이다. 봇은 당연히 시맨틱 HTML이나 웹 표준에 기반하여 크롤링을 할 수 밖에 없고, 이 것이 인간의 브라우징에도 긍정적인 영향으로 이어지는 지점을 많이 경험했다. 또 개발 방향성을 정할 때 명확한 근거가 되어 주기도 했다. 앞으로도 SEO, 웹 표준, 접근성으로 이어지는 이 맥락을 놓지는 않을 듯 하다.